A query I find myself often running is the online redo log switch frequency map query, which queries the v$log_history/gv$log_history (for cluster databases) view and show the historical log switch frequency.
Why you might ask? Well it’s important to see how frequent log switches are occurring as Oracle’s rule of thumb is to not switch more then 3 logs per hour (20 minutes of redo) at peak DML activity to prevent excessive checkpoints. The query can also highlight abnormal churn (DML activity).
Online Redo Log Switch Frequency Map Query
set pages 999 lines 400
col h0 format 999
col h1 format 999
col h2 format 999
col h3 format 999
col h4 format 999
col h5 format 999
col h6 format 999
col h7 format 999
col h8 format 999
col h9 format 999
col h10 format 999
col h11 format 999
col h12 format 999
col h13 format 999
col h14 format 999
col h15 format 999
col h16 format 999
col h17 format 999
col h18 format 999
col h19 format 999
col h20 format 999
col h21 format 999
col h22 format 999
col h23 format 999
SELECT TRUNC (first_time) "Date", inst_id, TO_CHAR (first_time, 'Dy') "Day",
COUNT (1) "Total",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '00', 1, 0)) "h0",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '01', 1, 0)) "h1",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '02', 1, 0)) "h2",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '03', 1, 0)) "h3",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '04', 1, 0)) "h4",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '05', 1, 0)) "h5",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '06', 1, 0)) "h6",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '07', 1, 0)) "h7",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '08', 1, 0)) "h8",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '09', 1, 0)) "h9",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '10', 1, 0)) "h10",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '11', 1, 0)) "h11",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '12', 1, 0)) "h12",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '13', 1, 0)) "h13",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '14', 1, 0)) "h14",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '15', 1, 0)) "h15",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '16', 1, 0)) "h16",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '17', 1, 0)) "h17",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '18', 1, 0)) "h18",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '19', 1, 0)) "h19",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '20', 1, 0)) "h20",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '21', 1, 0)) "h21",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '22', 1, 0)) "h22",
SUM (DECODE (TO_CHAR (first_time, 'hh24'), '23', 1, 0)) "h23",
ROUND (COUNT (1) / 24, 2) "Avg"
FROM gv$log_history
WHERE thread# = inst_id
AND first_time > sysdate -7
GROUP BY TRUNC (first_time), inst_id, TO_CHAR (first_time, 'Dy')
ORDER BY 1,2;
Online Redo Log Switch Frequency Map Output
SQL> set pages 999 lines 400
SQL> col h0 format 999
SQL> col h1 format 999
SQL> col h2 format 999
SQL> col h3 format 999
SQL> col h4 format 999
SQL> col h5 format 999
SQL> col h6 format 999
SQL> col h7 format 999
SQL> col h8 format 999
SQL> col h9 format 999
SQL> col h10 format 999
SQL> col h11 format 999
SQL> col h12 format 999
SQL> col h13 format 999
SQL> col h14 format 999
SQL> col h15 format 999
SQL> col h16 format 999
SQL> col h17 format 999
SQL> col h18 format 999
SQL> col h19 format 999
SQL> col h20 format 999
SQL> col h21 format 999
SQL> col h22 format 999
SQL> col h23 format 999
SQL> SELECT TRUNC (first_time) "Date", inst_id, TO_CHAR (first_time, 'Dy') "Day",
SQL> COUNT (1) "Total",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '00', 1, 0)) "h0",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '01', 1, 0)) "h1",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '02', 1, 0)) "h2",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '03', 1, 0)) "h3",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '04', 1, 0)) "h4",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '05', 1, 0)) "h5",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '06', 1, 0)) "h6",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '07', 1, 0)) "h7",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '08', 1, 0)) "h8",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '09', 1, 0)) "h9",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '10', 1, 0)) "h10",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '11', 1, 0)) "h11",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '12', 1, 0)) "h12",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '13', 1, 0)) "h13",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '14', 1, 0)) "h14",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '15', 1, 0)) "h15",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '16', 1, 0)) "h16",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '17', 1, 0)) "h17",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '18', 1, 0)) "h18",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '19', 1, 0)) "h19",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '20', 1, 0)) "h20",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '21', 1, 0)) "h21",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '22', 1, 0)) "h22",
SQL> SUM (DECODE (TO_CHAR (first_time, 'hh24'), '23', 1, 0)) "h23",
SQL> ROUND (COUNT (1) / 24, 2) "Avg"
SQL> FROM gv$log_history
SQL> WHERE thread# = inst_id
SQL> AND first_time > sysdate -7
SQL> GROUP BY TRUNC (first_time), inst_id, TO_CHAR (first_time, 'Dy')
SQL> ORDER BY 1,2;
Date INST_ID Day Total h0 h1 h2 h3 h4 h5 h6 h7 h8 h9 h10 h11 h12 h13 h14 h15 h16 h17 h18 h19 h20 h21 h22 h23 Avg
--------- ---------- --- ---------- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ----------
24-MAY-19 1 Fri 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 .04
24-MAY-19 2 Fri 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 .04
25-MAY-19 1 Sat 56 1 1 3 0 2 2 0 7 0 0 10 4 4 6 3 1 2 4 1 1 1 2 0 1 2.33
25-MAY-19 2 Sat 62 0 3 3 0 1 2 0 7 0 0 8 5 2 2 3 5 4 2 3 3 5 4 0 0 2.58
26-MAY-19 1 Sun 56 1 1 3 0 2 5 0 11 0 4 1 1 7 7 3 5 1 0 0 0 1 1 1 1 2.33
26-MAY-19 2 Sun 28 1 3 3 0 1 4 0 5 0 1 1 0 2 3 1 1 1 0 0 0 0 0 1 0 1.17
27-MAY-19 1 Mon 33 1 1 3 0 1 4 0 6 5 1 0 1 1 2 1 1 1 0 0 0 1 1 0 2 1.38
27-MAY-19 2 Mon 21 0 3 3 0 0 4 0 3 2 0 0 1 0 1 0 1 0 1 0 0 0 0 1 1 .88
28-MAY-19 1 Tue 43 2 3 3 0 3 5 1 4 3 1 3 0 1 1 1 1 2 3 2 1 1 0 1 1 1.79
28-MAY-19 2 Tue 38 2 4 3 1 1 4 1 7 1 1 1 1 0 1 0 0 2 4 0 1 0 1 1 1 1.58
29-MAY-19 1 Wed 58 2 4 4 1 3 5 2 12 3 1 3 1 2 5 4 1 1 0 1 0 1 0 2 0 2.42
29-MAY-19 2 Wed 28 0 2 3 0 1 4 1 5 1 0 1 1 0 2 1 1 1 1 0 0 1 1 0 1 1.17
30-MAY-19 1 Thu 39 2 3 3 0 1 5 1 7 1 1 2 3 1 2 2 1 0 1 1 0 0 1 0 1 1.63
30-MAY-19 2 Thu 29 0 1 3 0 2 4 1 4 2 1 1 1 1 1 2 0 1 2 0 0 1 1 0 0 1.21
31-MAY-19 1 Fri 153 2 1 3 0 2 4 1 8 3 0 23 29 10 2 1 18 20 6 12 2 3 3 0 0 6.38
31-MAY-19 2 Fri 223 1 2 3 0 1 4 0 3 1 0 71 86 29 1 0 6 7 2 4 0 1 1 0 0 9.29
16 rows selected.
SQL>
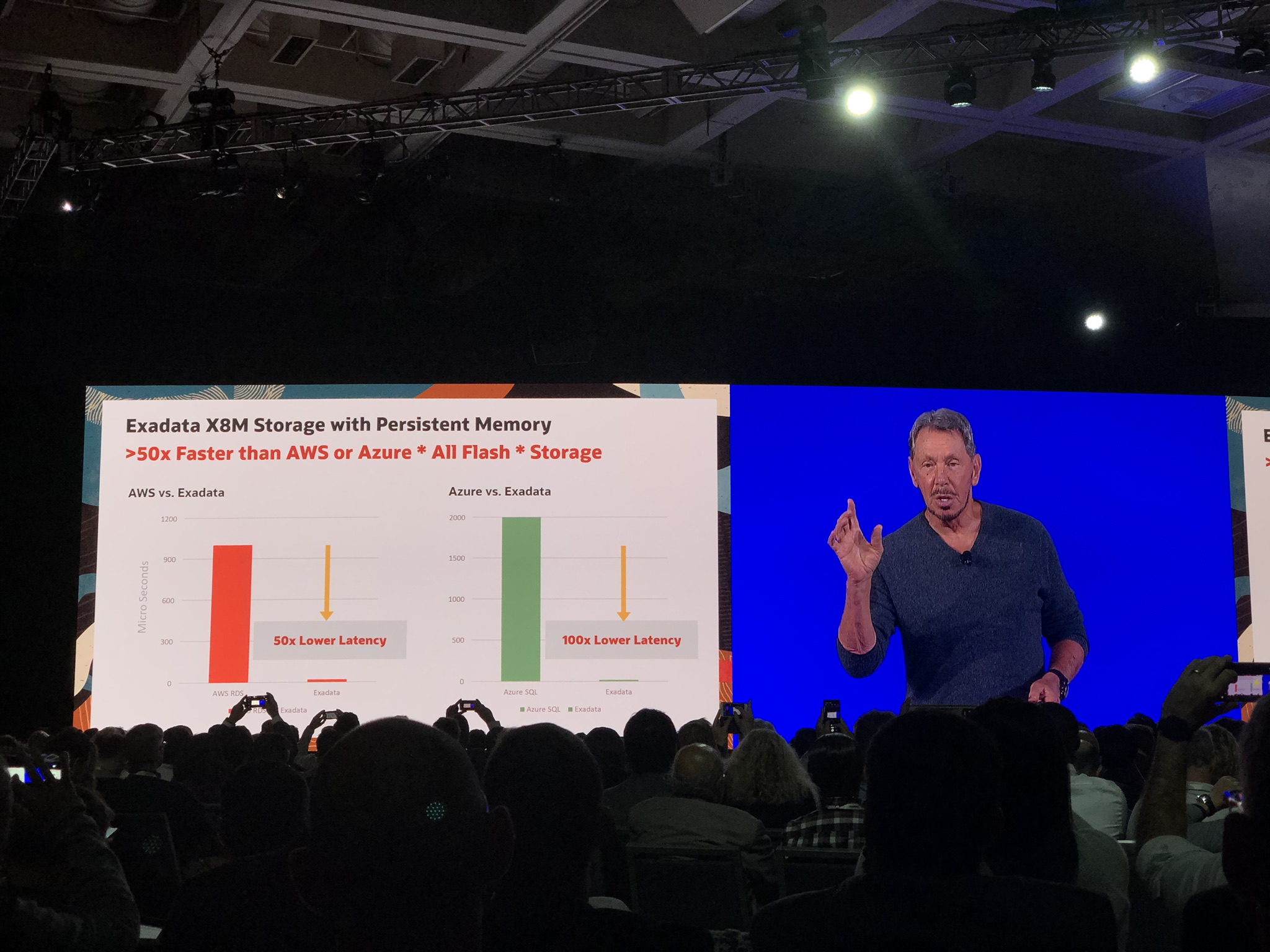
Where the log switch frequency exceeds 3 per hour, I have highlighted as red.
From the above output, we can see that most the time the 3 log switch per hour is met, with the 5th and 7th hour exceeding the threshold. Also we can see today there as been abnormal and excessive churn at 10th and 11th hour.
Investigating this further, we look at v$log to see the size of the online redo logs:
SQL> set pages 999 lines 400
SQL> col FIRST_CHANGE# format 999999999999999
SQL> select GROUP#, THREAD#, SEQUENCE#, BYTES/1024/1024 SIZE_MB, BLOCKSIZE, MEMBERS, ARCHIVED, STATUS, FIRST_CHANGE#, FIRST_TIME, NEXT_CHANGE#, NEXT_TIME, CON_ID from v$log;
GROUP# THREAD# SEQUENCE# SIZE_MB BLOCKSIZE MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM NEXT_CHANGE# NEXT_TIME CON_ID
---------- ---------- ---------- ---------- ---------- ---------- --- ---------------- ---------------- --------- ------------ --------- ----------
1 1 40649 4096 512 2 YES INACTIVE 137921001754 31-MAY-19 1.3793E+11 31-MAY-19 0
2 1 40650 4096 512 2 NO CURRENT 137930464620 31-MAY-19 2.8147E+14 0
3 1 40648 4096 512 2 YES INACTIVE 137920121808 31-MAY-19 1.3792E+11 31-MAY-19 0
4 2 39319 4096 512 2 NO CURRENT 137921005288 31-MAY-19 2.8147E+14 0
5 2 39317 4096 512 2 YES INACTIVE 137917291807 31-MAY-19 1.3792E+11 31-MAY-19 0
6 2 39318 4096 512 2 YES INACTIVE 137919186475 31-MAY-19 1.3792E+11 31-MAY-19 0
6 rows selected.
SQL>
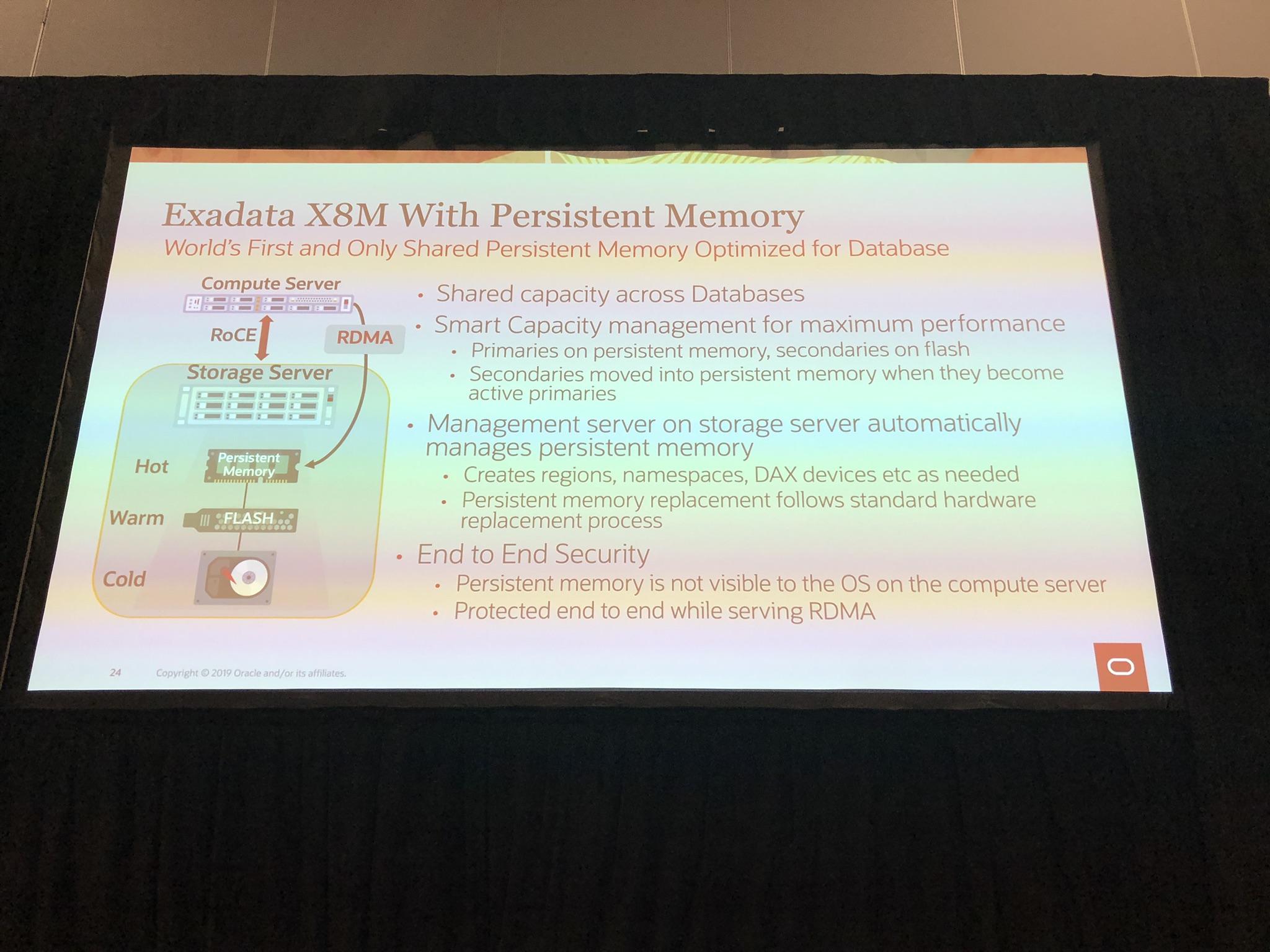
As we can see the online redo logs are 4GB, which is the default size on Oracle Exadata, which this is. We could increase the size of the redo logs but it trade-off between performance verse space usage. The peak we can see was 29 log switches for instance 1 and 86 log switches for instance 2, assuming these were full redo logs before switching, this is 29 + 86 logs switches for the database. Which is 115 for the the hour, equating to a significant 460 GB of churn! But this is an Exadata Machine and is sized and designed for this sort of load 🙂 To resize the redo logs to switch only 3 per hour, we would need to resize to 154GB, this wouldn’t be feasible, so we could either increase to something more reasonable like 10GB or leave as is, depending on what more important, the performance or space usage.
If you found this blog post useful, please like as well as follow me through my various Social Media avenues available on the sidebar and/or subscribe to this oracle blog via WordPress/e-mail.
Thanks
Zed DBA (Zahid Anwar)