UKOUG Conference ’23
If you missed my day 1, you can view it here.
Last night was the UKOUG Evening Celebration ’23, and although it finished at approximately 11:30pm, it took the team and board a couple of hours to pack up, debrief and have the traditional late night takeaway as some of us get too busy with the event, we don’t get a moment to eat properly or at all 🙁
Due to the late night, I skipped the first session and arrived for second session, however decided I’d use the hour to go over my presentation as I was presenting later in the day.
I had then planned to attend Kerry Osborne session, however one problem, Kerry wasn’t there! I checked with the team and they said he was delayed getting to the venue. So I looked who was around and saw Nigel Bayliss was around, and asked if he could fill the slot with any material he had already presented recently, as we had 50-100 people in the Ozone waiting for a presentation 🙄. He suggested Dom Giles, who kindly agreed to present minutes before the start time.
It was greatly appreciated, and Dom Giles presented “Oracle Database: What’s New, What’s Coming” which is what he presented at the recent Oracle DatabaseWorld at CloudWorld:
He talked about many new features in 23c and also what was coming. One of these new features that coming, was True Cache, which is similar to Redis which you put cache in front of the application to improve performance for data that doesn’t need to be most current data:
He also spoke about performance enhancements in 23c:
Finally concluded on database release and support timeline, the key being that 19c waived extended support increased by a year and 23c projected release in early 2024:
Whilst Dom was presenting, the UKOUG team had informed me that Kerry had arrived. So I went and spoke to him, luckily the next hour slot in Ozone was free as it was lunch, so I advised the audience that once Dom was finished, that Kerry would delivery his presentation in that free slot and they were free to stay and listen.
Next I attended “How to Improve Your Ability to Solve Complex Performance Problems” by Kerry Osborne, Google:
Has he had issues with his laptop, he decided to abandon his slides but still go through the process of how to solve complex performance problem, broken down into 3 parts:
- Explain the basic process we must go through to solve a complex performance problem
- Discuss some of the main factors that can inhibit our efforts
- Discuss some of the techniques we can apply to improve our chances
It was interesting to hear from his 20 years of experiences, tips and tricks as well as experiences of working with of the best performance troubleshooters in the world.
Next, I went to have a light lunch and head to my next session which is unusual for me to attend, but as I’ve heard so much about CX lately, I thought it was worthwhile attending “Innovation with Oracle Intelligent Advisor” by Leona Chauhan:
Very interesting session, where I came to understand that Oracle Intelligent Advisor is a rules engine technology that is purpose built for automating complex policies and creating tailored personalised applications. For example, a company may have a complex maternity policy, that have large ruleset, that could be converted to rules and an application created off the back of these rules that will be used to question/interview the users and provide tailored response on their entitlement. The impressive part, was the tooling can take policy document and parse them into rules, which then can be refined into the final set of rules which the application is built off.
One of the key features is it automates decision-making, carrying out complex calculations, yet has a low code interface for development. This can save thousand of hours reducing errors in applications by intelligent online interviews, which can respond automatically, giving instant decision in a downloadable letter or form, which mirrors policy or process documents.
It can be embedded within a public webpage or private intranet site and can be integrated into ERP system, which can be on-premises or cloud. It is very flexible and is instrumental in giving the best customer experience.
Next what my own session “Harnessing the power of Oracle Exadata Database Machine“:
Where I talked about the “Oracle Secret Sauce”, well more it’s just simply Brawn Hardware with Smart Software. And it’s the integration of hardware and software that sets apart Exadata from the rest, as Oracle says: “Hardware and Software: Engineered to Work Together”.
I also went through:
- Why move to Exadata
- The benefits
- What’s new in X10M (see blog post here for more info)
- Migration Challenges
- Tips and Tricks/Best Practices
- How to tackle database consolidation
- Different types of Exadata offerings/Responsibility Model
- And of course, harnessing the power of Oracle Exadata Database Machine
Once my presentation was done, I was able to relax and attended “A Practical example of implementing TDE and TLS1.2 in an Oracle 19c Data Guard Environment” by Clive Archibald, Virgin Media O2:
This was delivered by one of my clients, Clive, who I have worked for nearly 10 years on their Exadata estate supporting their Smart Metering:
He went through a comprehensive example of how Virgin Media O2 had setup TLS 1.2, using certificates Azure Key Vault to manage them. Also went through example of how TDE was implemented.
Then came the final session of the conference (the best for last 😉), which I attended “Exadata: Strategy and Roadmap for New Technologies, Cloud, and On-Premises” by Alex Blyth, Oracle:
He first spoke about what Exadata is and the vision:
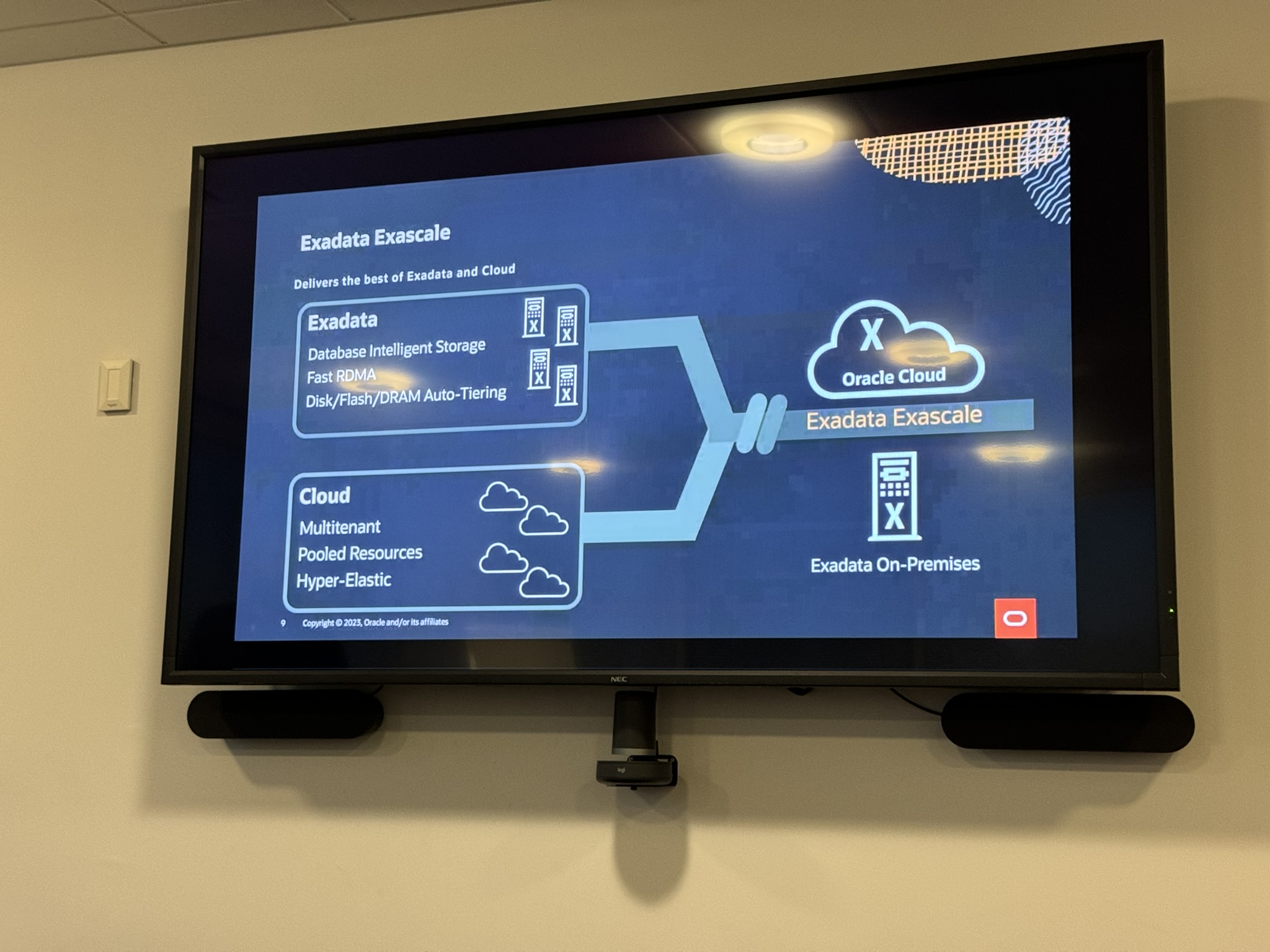
He then went onto discussing Oracle Exadata Exascale:
An exciting new feature, that uses Exadata platform to cater for broad spectrum of requirements, from small configurations to large deployment:
This is similar to how Autonomous database (shared infrastructure) can be consumed from a core and 1TB storage up to thousands of cores and petabytes of storage. It’s great for hyperscale, which Alex said selfishly Oracle needed for Oracle Cloud, but is also great for customer to use in the Oracle Cloud or on-premises, to allow for flexible elastic architecture.
Also, what great is state of the art storage efficient database cloning, meaning no more Exadata Sparse Clones with test master! Actual space efficient redirect on write technology:
Exadata Exascale, will facilitate a new OCI Exadata Database Service namely ExaDB-XS:
This will provide to be very flexible, elastic and cost efficient! It’s a really interesting space, which I look forward to:
So in summary, next gen software architecture, simple, flexible, efficient, foundation for multi-tenant Exadata Database Service:
Once the presentation was over, it was a case of wrapping up the conference, working with the team removing all the branding, pack up and leaving with the conference blues 😕:
Till next time! Hope to see you all soon!
If you found this blog post useful, please like as well as follow me through my various Social Media avenues available on the sidebar and/or subscribe to this oracle blog via WordPress/e-mail.
Thanks
Zed DBA (Zahid Anwar)