If you missed my day 1, you can view it here.
Day 2 was about registering for Oracle AI World, then attending Empower Your Clients: Oracle Database Security Partner & ACE SIG session, the Oracle Partner Success Summit, and finally the Database Premier Customer Appreciation Event in the evening.
Registering for Oracle AI World
I spent the morning blogging about day 1 followed by having breakfast, the same healthy sourdough bread, lightly boiled eggs with avocado.

Like last year, Oracle AI World is only in The Venetian, with no other Oracle-related conferences going on in parallel like JavaOne or SuiteWorld. I headed over at midday to register, and it was starting to get busy.



I headed over to registration, and luckily it wasn’t busy. I saw on social media in the morning, the queues were huge as everyone tried to register early.


The slogan at the registration desk said, “AI Changes Everything”, setting the tone for the conference. Within a couple of minutes, I was registered 😎

Empower Your Clients: Oracle Database Security Partner & ACE SIG
There were no official sessions today, with the exception of the Oracle Partner Success Summit, unless by invitation. Being an Oracle ACE, I got invited to the Empower Your Clients: Oracle Database Security Partner & ACE SIG for Oracle partners and Oracle ACEs. So I attended this session before attending the Oracle Partner Success Summit.

Vipin Samar, Senior Vice President of Development for Database Security, Oracle, talked about risks to your database that can come from many directions, hence “RISK360”.

How, if any gaps remain open, these will be exploited, hence it’s imperative we protect against all attack vectors.

How, the challenge is we don’t have just one database but many! So how do we address the challenge of an entire database fleet with different requirements and an evolving landscape that we need to constantly keep updating?

He talked about a three-pronged approach of:
- Security 360: securing the database attack surface
- Security at source: where possible, secure at source, so not relying on other external measures you may not have control over i.e. row, column, and cell-level control
- Security at scale: so not just apply to one database but the entire fleet

Next, he spoke about how to address those risks with various Oracle products, features, or processes.
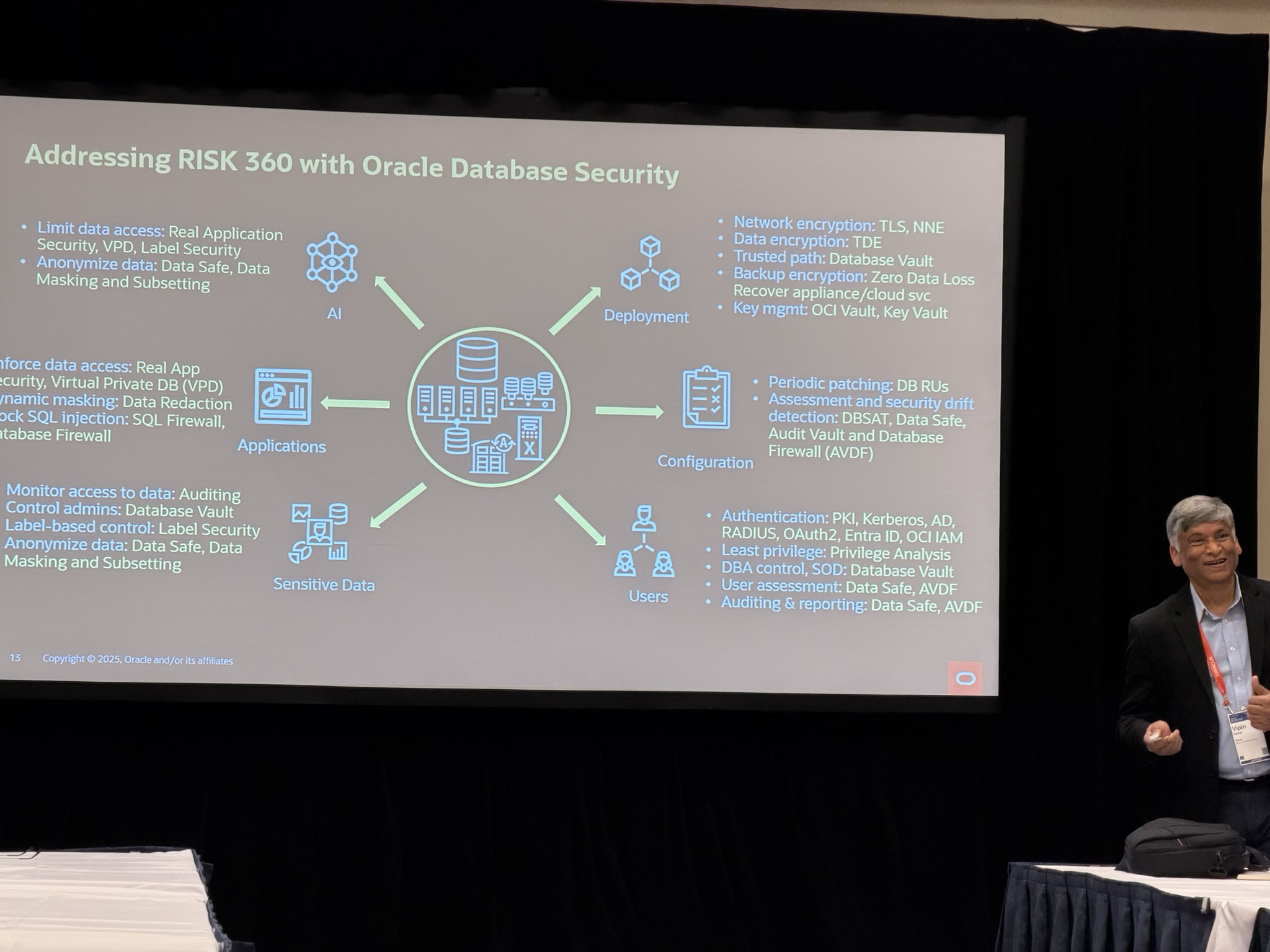
Then he spoke about how to address security at scale with Oracle Data Safe, an Oracle Cloud product, which can be used to manage databases in OCI, multi-cloud, or even on-premises. Securing thousands of databases anywhere.



Next, Vikram Pesati talked about how to secure agentic AI from providing more information than the requester is privileged to see. Ensuring no unauthorised access by bypassing typical permissions. Ensuring row and column-level control.



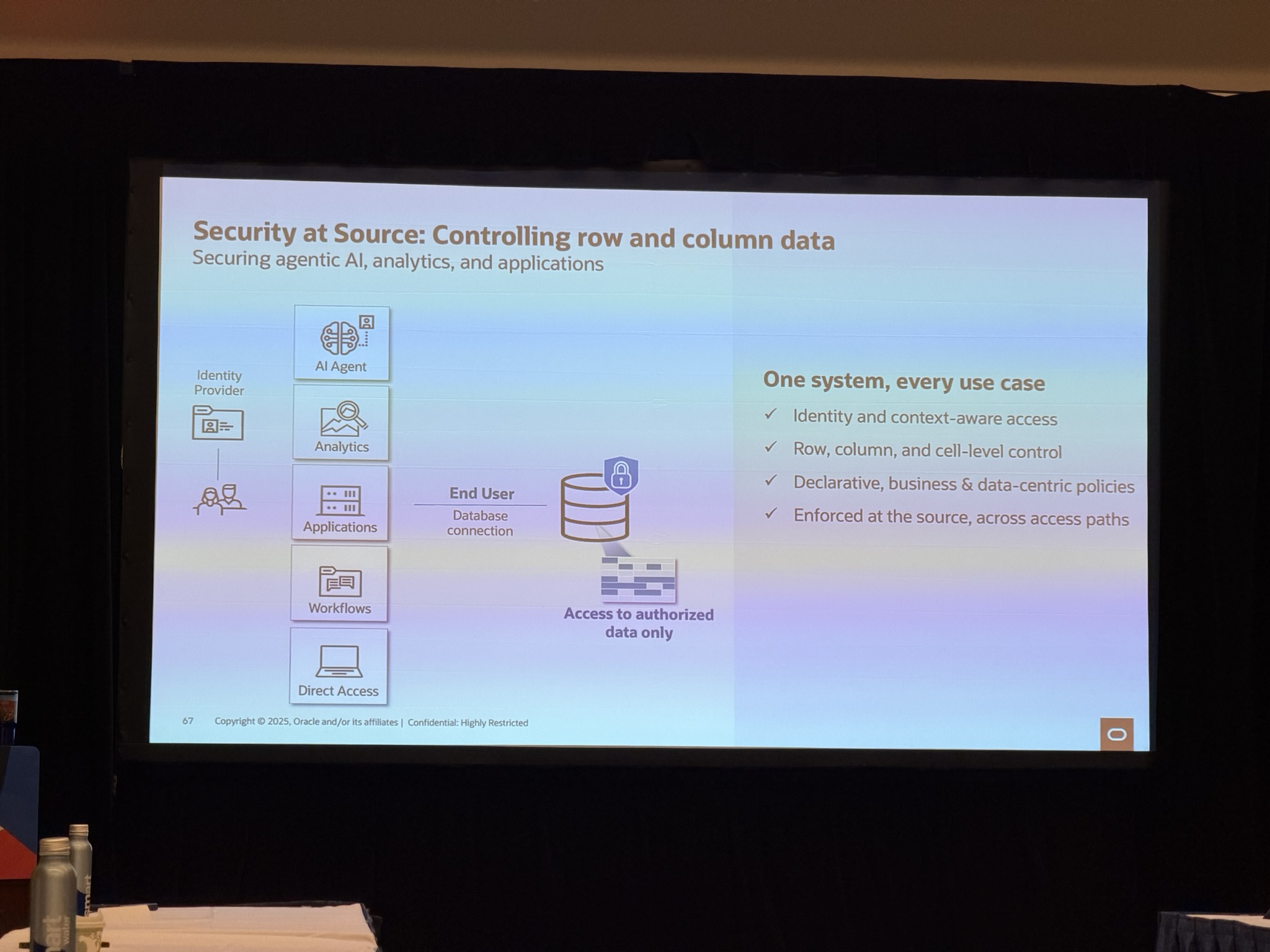
As the Oracle Partner Success Summit was starting shortly, I had to leave this session early to ensure I got a good seat.
Oracle Partner Success Summit
I headed over to the Partner Success Summit, where the doors had already opened. I headed over to the front, as close as I could get. The room was starting to get pretty full.


Same as last year, Leah Yomtovian, Senior Vice President, Partner, Sales, and Operations Strategy was the host and welcomed us all. However, it was evident she was pregnant, congratulations to her! 😊

She:
- Thanked us all for helping deliver exceptional customer outcomes
- Mentioned how we’re already off to a great start this year with increases in cloud and OCI revenue, with even more cloud regions
- Stated how lower costs in OCI mean customers are doing more whilst spending less
- Also stated higher AI performance on OCI compared to other hyperscalers
- Mentioned how reliable and trusted security is built into the Oracle DB
- Mentioned cloud applications that are integrated, scalable, performant, and capable of running mission-critical applications
- Explained how we all can help customers leverage AI to solve complex challenges through Oracle Cloud Apps, Oracle AI Database, or Oracle Cloud Infrastructure




She then welcomed Clay Magouyrk, CEO, Oracle (newly appointed from President of OCI business), to the stage.




I’ve always admired Clay, as he’s a true techie at heart, not the most eloquent person, but he owns it and has that appeal with the techies because he can speak at a low level.
He spoke about several key themes:
- OCI underpins Enterprise Applications and also functions as a standalone product. Years of investment have driven its success
- OCI can scale up or down, even to a minimal footprint of just three racks, making it highly flexible
- In multi-cloud setups, Oracle embeds its full stack, infrastructure, software, network, so that new features are instantly available across environments, including Google Cloud, Azure and AWS
- Oracle ensures the same services are available everywhere in OCI, maintaining consistency across regions and platforms
- Introduced Zero Trust Packet Routing, a new feature that enforces zero trust principles at the network layer. It restricts access to OCI resources based on security attributes and intent-based policies, such as limiting access to Object Store
- Emphasised that security is as critical as performance, with built-in guardrails and compliance with global standards
- At both the platform and application layers, Oracle sees a huge opportunity to adopt AI
- The AI and data platform enables enterprises to leverage the latest AI capabilities, with embedded AI that is secure, intuitive, and built into workflows
- Oracle’s AI is natively built into OCI, not bolted on, and is automatically updated with no extra cost
- “AI is changing everything”, we’re in a fundamental period of transformation. Clay urged partners to understand what’s new, what’s changed, and how AI can reshape businesses
- The Oracle Database is the best place to take advantage of AI, available on-premises and across all clouds
- Partners like you are key drivers of this change, helping customers unlock the full potential of Oracle’s AI and cloud offerings
Leah next welcomed Hasan Rizvi, EVP, Database Engineering, Oracle and Srikant Gokulnatha, SVP, Analytics Product Management, Oracle to the stage.




Hassan talked about:
- How the Oracle Database was the first relational, first portable, first clustered, first engineered, first autonomous, and now the first AI-native database
- The first converged database: a single engine with native support for all modern data types, analytics, and development paradigms built into one product
- Portability and flexibility allow customers to decide where they want to run workloads, on-premises, Cloud@Customer, or multi-cloud environments like AWS, Azure, and GCP
- Security close to the data is a third pillar of Oracle’s strategy, making a big difference to customers by enforcing zero trust principles and quantum-resistant encryption
- Leveraging the power of AI and data together by bringing AI to your data, not the other way around. This is enabled by in-database AI agents, vector search, and retrieval-augmented generation (RAG) capabilities
- Introduction of new vector data types for AI and agentic RAG, allowing SQL queries across both vectors and relational data
- Functionality to explain data using annotations, helping machine learning models generate SQL and improve interpretability
- Development transformation through low-code apps built on Oracle APEX, powered by ML-generated logic
- Oracle Database is now available everywhere, on all three major hyperscalers (AWS, Azure, GCP), on-prem, and OCI, giving customers the freedom to choose
- Customers can bring their Oracle licences or use their hyperscaler contracts to consume Oracle services, offering commercial flexibility
- Oracle continues to deliver the highest performance, especially on Exadata and the newly announced OCI Zettascale10 supercomputer, which supports 16 zettaflops of AI compute
- The combination of multi-cloud, AI, ZDLRA (Zero Data Loss Recovery Appliance), and Autonomous AI Lakehouse opens up massive opportunities for partners and customers alike
Srikant talked about:
- Gartner’s 60% prediction: By 2026, 60% of enterprise data will be used to train AI models, highlighting the urgency to make data AI-ready
- The importance of making data ready for AI by ensuring it is clean, structured, and accessible across platforms
- How to bring data together from disparate sources into a unified model, this is where Oracle Fusion Data Intelligence (FDI) plays a key role
- Exposing data as one unified layer for AI consumption, enabling consistent access for training and inference across Oracle Cloud Applications
- Use of low-code tools like Jupyter and Oracle AI Agent Studio to build agentic AI solutions. These tools allow developers and analysts to create AI workflows without deep ML expertise
- Fusion Data Intelligence (FDI) as a platform for agentic AI
- FDI integrates with Oracle ERP, HCM, SCM, and CX to provide prebuilt KPIs, dashboards, and AI/ML models
- It supports custom ETLs, third-party analytics tools, and self-service reporting
- FDI enables 360-degree views of business entities, combining transactional and analytical data for deeper insights
- Oracle’s broader data and analytics strategy creates rich opportunities for partners to deliver AI-driven solutions that are scalable, secure, and business-aligned
Next, Leah welcomed Mike Sicilia, CEO, Oracle (newly appointed from President of Oracle Industries) and Steve Miranda, Executive Vice President, Application Development, Oracle to the stage.



Mike Sicilia and Steve Miranda talked about:
- Over 400 AI features embedded in Oracle Fusion Applications, and 650+ AI capabilities across industry-specific apps like Oracle Health, Hospitality, and Financial Services
- The deployment of AI agents to solve real business problems, not just automate tasks. These agents are designed to triage, fetch data, generate responses, and trigger actions, acting like digital team members
- Introduction of AI Studio for Fusion and industry apps, enabling partners and customers to customise or build new agents using low-code tools like Jupyter notebooks and Oracle Agent Studio
- Emphasis on prompt engineering and private data residency within applications, ensuring AI operates in close proximity to enterprise data for better accuracy and security
- Oracle’s unique position as the only vendor with deep integration across both applications and technology stack, allowing it to drive real business value rather than just data movement
- A compelling healthcare example: Oracle AI saved 100 minutes per day in clinical settings by automating mundane tasks, such as documentation and scheduling
- Focus on real applied AI, not hype, to deliver efficiency gains by removing labour-intensive processes and enabling automation at scale
- A heartfelt appreciation for the partner community, recognising that partners working closely with customers are the key to driving success and adoption
- Advice to partners: understand the full Oracle stack, from infrastructure to apps, to help customers solve complex, multi-layered problems that require deep integration
Next, Leah had her own segment.










She talked about:
- Helping customers move Oracle applications to the cloud, particularly Fusion Cloud Applications, to unlock agility, scalability, and embedded AI capabilities
- Encouraging partners to engage C-level stakeholders to help them understand the strategic value and opportunity of Oracle’s full-stack cloud and AI offerings
- Leveraging OCI and AI agents to deliver joint solutions that solve real business problems. This includes deploying Oracle-validated AI agents built by partners and available directly within Fusion workflows
- Driving organisational transformation through Oracle’s end-to-end tech stack, from infrastructure to applications, enabling seamless integration and automation
- Highlighting the launch of the Oracle AI Agent Studio and its listing on the Oracle Marketplace, where partners can publish and monetise their AI agents with custom pricing models approved by Oracle
- Promoting free AI training for partners, available through Oracle University until end of October, covering topics like Fusion ERP, HCM, and APEX low-code development with AI.
For the final segment, Leah welcomed Karen Chen, VP, Global Cloud Sales, nvidia to the stage.


She talked about:
- DGX-1 (2016) marked NVIDIA’s pivotal shift into deep learning, integrating chip, software, and networking capabilities
- This led to its first partnership with OpenAI, laying the groundwork for modern AI infrastructure
- The GH200 Grace Hopper Superchip, now available in Oracle Cloud Infrastructure (OCI), exemplifies NVIDIA’s commitment to high-performance computing for generative AI workloads
- NVIDIA AI Enterprise provides a robust software layer for deploying AI across hybrid cloud environments, including OCI
- The NVIDIA Inference Service in OCI supports scalable AI workloads, particularly in data science and model deployment
- Karen emphasised that the partner ecosystem plays a vital role in accelerating AI adoption, with collaboration being critical to NVIDIA’s success
- The session reinforced how strategic partnerships and cloud-native AI services are driving rapid innovation and enterprise transformation
After the summit concluded, a network reception was held for approximately 500–600 partner delegates, which I attended. During the event, I had the opportunity to connect with Manish Naik, another Oracle ACE, and catch up with my Version 1 colleagues, Tim German, Kate Mead, and Marc Southey.


Oracle Database Premiere Customer Appreciation Event
The final event of the day was the Oracle Database Premiere Customer Appreciation Event, which I’ve attended for the past three years. For the last two years, and again this year, the event was hosted at Madame Tussauds in The Venetian, offering a familiar and engaging setting for networking!
Met with my Oracle ACE friends, Vijayganesh Sivaprakasam, Osama Mustafa, Nelson Calero, and Sai Penumuru.





There was a fun and visually impressive ice cream-making experience this time, using liquid nitrogen, a popular technique for its dramatic fog effect and ultra-fast freezing, which always draws a crowd and tasty at the same time 😋

I got to met Annie, from Barclays a customer of Version 1.

A little bit of fun with angel wings, a light-hearted moment with my Oracle ACE friends!



I also got to meet Alex Blyth, Exadata Product Manager, who I know quite well 😊
As well as:
Also got to meet some old friends from last year when I attended the same event 🤣

Rather then repeating the same photos, you can see them here:
Tomorrow marks the first day of the actual conference, really looking forward to it! 😎👍🏽
You can view my day 3 part 1 here.
If you found this blog post useful, please like as well as follow me through my various Social Media avenues available on the sidebar and/or subscribe to this Oracle blog via WordPress/e-mail.
Thanks
Zed DBA (Zahid Anwar)




































































































